Visual Field Test
Mede a função visual e a sensibilidade retiniana.
Como é feito
O paciente olha para um ponto central dentro de uma cúpula (o Humphrey Field Analyzer - HFA) e deve apertar um botão sempre que vir um flash de luz em diferentes posições periféricas. A máquina tem o objetivo de descobrir o threshold de sensibilidade. Ela faz isso através de um interrogatório luminoso:
- Ela pisca uma luz fraca naquele ponto fixo. Se você não apertar o botão (não viu), a máquina anota e, rodadas depois, pisca uma luz mais forte no mesmo lugar.
- Se você apertar o botão, ela tenta uma luz ainda mais fraca.
- Ela faz esse "sobe e desce" de intensidade até encontrar o ponto exato de luminosidade (o estímulo mais fraco possível) que você consegue enxergar com 50% de probabilidade.
Métricas
O exame de campimetria gera um mapa de sensibilidade. Métricas como o MD/MTD e PSD saiem impresssas no papel do aparelho no consultório, variam.
Pointwise
Valores ponto a ponto na amostra do exame
Sensibilidade
Raw Sensitivity é a medida gerada pelo aparelho de campimetria. Representa a intensidade mínima de luz (medida em decibéis - dB) na qual o paciente consegue perceber um estímulo luminoso com 50% de probabilidade em uma localização específica da retina. Valores mais altos significam que o paciente tem uma visão melhor (pois ele conseguiu enxergar uma luz muito fraca/tênue). Áreas com baixa sensibilidade indicam escotomas (pontos cegos) e perda de visão.
TD - Total Deviation
É a diferença ponto a ponto entre a sensibilidade bruta e a sensibilidade que se espera para a idade do paciente. O objetivo do TD é anular a perda de visão natural que ocorre com o envelhecimento humano. Mostra o dano real isolado: valores próximos a zero são normais, enquanto valores muito negativos indicam perda funcional naquela localização exata. Onde:
- : sensibilidade bruta
- : sensibilidade bruta esperada pela idade do paciente
Corrige as varaições no VF relacionadas à idade e à localização
Importante ressaltar que, mesmo para um exame de um paciente com idade x, o é diferente para cada ponto. Isso ocorre porque a sensibilidade humana não é plana. O centro da nossa visão (perto da fóvea) é naturalmente muito mais sensível à luz do que a visão periférica. Portanto, o para um ponto central é um valor bem mais alto do que o para um ponto na borda do exame. Ou seja, normaliza tanto tirando o envelhecimento natural do paciente quanto removendo o efeito de "Colina de visão"/#Hill of vision. (A visão humana tem o formato de uma "colina", sendo naturalmente muito mais sensível e responsiva no centro da mácula do que na periferia). Outro ponto é que os valores normativos por idade são fechadas no código do aparelho no caso do HVF.
Resumo: Diferença matemática entre a sensibilidade bruta medida e o valor normativo que seria esperado para uma pessoa perfeitamente saudável da mesma idade. Ele corrige a perda natural de visão causada pelo envelhecimento e a topologia natural do olho.
PD - Pattern Deviation
Mapa que isola defeitos focais (regiões) removendo a depressão difusa (quase todos os pontos ficam mais “baixos”) estimada pelo GH.
(Equivalentemente, subtrai-se o 7º maior TD de todos os pontos).
Interpretação
- Se TD mostra um defeito, mas PD não mostra → defeito é difuso/generalizado (provavelmente não-glaucomatoso).
- Se PD mostra defeito igualmente focal ao TD → defeito é localizado (perfil glaucomatoso típico).
- O mapa de probabilidade do PD é o gráfico mais importante para diagnóstico precoce de glaucoma — defeitos arqueados, degraus nasais, defeitos paracentrais aparecem aqui mesmo quando MD ainda é normal.
Limitações
- Em glaucoma avançado, o GH é mal estimado (ver §4) e o PD passa a subestimar a perda focal.
- Em pacientes com catarata + glaucoma, há controvérsia: PD pode subestimar dano real (Rao et al., 2015).
Global
Métricas/escalares que resumem o teste completamente
MD - Mean Deviation
Uma métrica de resumo que avalia o rebaixamento geral/médio do campo visual em relação à população normal É a média aritmética de todos os valores de TD do exame inteiro.
PSD - Pattern Standard Deviation
Desvio-padrão dos valores de TD em relação à hill of vision esperada — quantifica quão irregular é o campo (i.e., quanto há de perda focal).
- Normal: 0 a ~6 dB (sempre positivo).
- Cutoff clínico: PSD com p < 5% é critério de Anderson-Patella para glaucoma.
Interpretação
- PSD baixo → campo "uniforme" (normal, ou globalmente deprimido sem focalidade).
- PSD alto → defeitos focais presentes (perfil glaucomatoso).
- Comportamento não-monotônico: à medida que o glaucoma piora, PSD aumenta (mais focalidade) e depois diminui (perda virou difusa). Por isso PSD perde valor em doença avançada.
Limitações
- O artigo do Mock (LocalPSD) já mostrou matematicamente que PSD destrói informação espacial — dois campos com PSD idêntico podem ter padrões topograficamente opostos.
GH - General Hight
Estimativa robusta da altura geral da #Hill of vision do paciente em relação ao normativo. Representa o quanto o campo inteiro está "achatado" por um efeito difuso (ex.: catarata). A convenção é de percentil 85 dos 52 valores de TD, equivalente ao 7º maior valor de TD. Já Marin-Franch et al. (2014) propõem o ajuste: . Onde 1,8 dB é o GH médio em uma população saudável.
Interpretação
- GH baixo (próximo de 0) → campo sem depressão difusa relevante.
- GH alto → campo globalmente deprimido (suspeitar de catarata, miose, efeitos não-glaucomatosos).
Limitação clínica
A regra do "7º maior" assume que pelo menos 15 % dos pontos permanecem não-danificados — premissa que falha em glaucoma avançado, levando a:
Garway Health Map
Hill of vision
Representação topográfica tridimensional da sensibilidade natural da visão humana ao longo do VF. A altitude da montanha representa o quão bem se enxergar um ponto de luz (sensibilidade ao contraste):
- Pico: O topo dessa colina fica exatamente no centro da nossa visão, correspondendo à fóvea (na mácula). É a área com a maior sensibilidade luminosa. Nesse ponto, o olho consegue detectar estímulos de luz muito fracos e tênues.
- Encostas: À medida que nos afastamos do centro em direção à visão periférica (aumento da excentricidade), a sensibilidade luminosa cai de forma gradual. Isso forma as ladeiras da montanha. É por isso que pontos na borda do exame precisam de uma luz mais forte para serem vistos do que os pontos no centro.
- Buraco: Na encosta temporal dessa colina, existe um "poço" profundo e abrupto. Ele corresponde à mancha cega fisiológica (o disco óptico), onde a sensibilidade cai a zero.
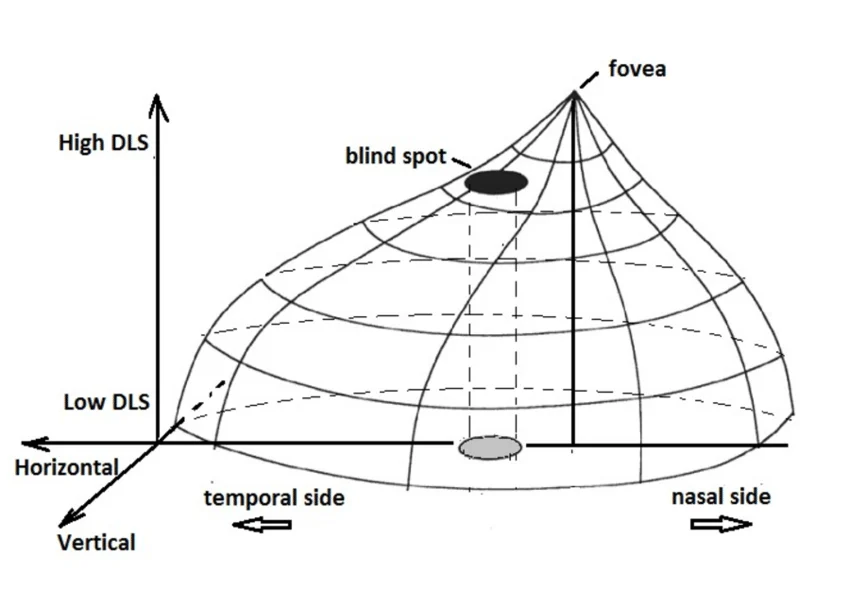 A perimetria estática (ex: Humphrey 24-2) funciona testando pontos fixos para medir a "altitude" (a sensibilidade bruta em decibéis) na montanha. É como se, em vez de escanear a montanha inteira, fizesse 52 "furos" estratégicos no solo para medir a altitude apenas naquelas coordenadas exatas.
A perimetria estática (ex: Humphrey 24-2) funciona testando pontos fixos para medir a "altitude" (a sensibilidade bruta em decibéis) na montanha. É como se, em vez de escanear a montanha inteira, fizesse 52 "furos" estratégicos no solo para medir a altitude apenas naquelas coordenadas exatas.
Forecasting de VFs
Este é meu tema de TCC. Criar e avaliar modelos de deep learning para fazer a previsão de exames de Humphrey Visual Fields 24-2.
Dataset
- Nome: UWHVF
- Ano: 2022
- Total HVFs: 28.943
Limitações
- Séries curtas: apenas 40.3% dos olhos (séries) possuem 4 ou mais amostras. Apenas 9.3% têm . Mediana de 3 exames por olho. Ou seja, até tem bastante séries, mas elas são curtas.
- Ruídos: dados de exames de campimetria são intrinsicamentes ruídosos, até pela dinâmica do aparelho. Exemplo: o paciente pode estar cansado no dia, na primeira consulta ele pode não entender bem a dinamica do aparelho/ quando apertar o botão. O resultado flutua.
- Não rotulado: não há uma classificação se o olho/exame é glaucomatoso/doente, suspeito, ou normal. Isso impede estratificação e torna difícil saber se você está tentando prever progressão de glaucoma ou simplesmente variação normal da perimetria.
- Desbalanciado: Apenas 23.8% dos olhos mostram progressão estatisticamente significativa. O modelo vai ver majoritariamente olhos estáveis — o que pode fazer ele aprender a "chutar estável" e ter boa métrica mesmo assim.
- Amostragem irregular: o espaço de tempo entre as amostras das séries é irregular. Ao comparar as séries, o CV (coeficeinte de variação) de tempo entre os exames da série tem uma mediana de 0.49.
Problema
Séries Temporais o input. Regressão o output.
Métricas
como avaliar se os forecastings de HVFs inferidos pelo modelofoi bom?
[[Regression#MAE|MAE]]
Mean Absolute Error diferenças absolutas entre as sensibilidades previstas e as reais.
PMAE
Point-wise MAE. para avaliar o erro específico ponto a ponto na grade de teste do campo visual/
Literatura
1. Modelos estatísticos
O objetivo no geral foi de superar os limites da Regressão Linear tradicional (Chamada tambem de OLSR). 10 HVFs para uma boa predição de sensibilidade.
2015 Taketani et al: avaliou vários modelos (OLSLR, exponencial, quadrático, logístico e regressão robusta M-estimator). M-estimator foi o melhor
2015 Fujino et al: Lasso. o objetivo principal do artigo foi prever o MTD do décimo exame usando sequências de testes anteriores, NÃO foi pointwise. dataset privado (247 olhos de 155 pacientes (sequências de 15 VFs))
2015 Zhu et al: ANSWERS. análise de séries temporais longitudinais e regressão pointwise. dataset privado (777 olhos de 416 pacientes)
2. Modelos de ML/DL
virada para o uso de redes neurais profundas e aprendizado de máquina para modelagem temporal com espacial
2019 Garcia et al: Filtros de Kalman. INÚTIL para o TCC (foi multimodal e nao focou em forecasting pointwise)
2019 Park et al: LSTM (sequência fixa de 5 exames prévios para prever o 6º). RNN obteve erros de predição significativamente menores em áreas vulneráveis ao glaucoma em comparação à regressão linear. Utilizaram dataset privado (train data com 1.408 olhos de 841 pacientes); Teste de 281 olhos (usados sequencialmente 5 VFs para prever o 6º))
2019 Wen et al: CascadeNet-5 via transfer learning. dataset privado de universidade de washington, posteriormente originou no UWHVF. Foram 32.443 VFs de 4.875 pacientes (3.972 no treino e 903 no conjunto de teste). O problema de Wen é bem mais complexo, ele não é um forecasting com série temporal. Tenta fazer o forecasting a partir de um exame só. repo.
2019 Berchuck et al: VAE. Utilizaram dataset privado (29.161 HVFs pertencentes a 3.832 pacientes).
2023 Kim et al: Bi-GRU (foi melhor que o LSTM).
2023 Pham et al: INÚTIL para o TCC (foi multimodal com imagens de OCT). repo
2024 Wang et al: ConvLSTM. O artigo fala que, enquanto Wen 2019 (CNN) "apenas o espaço" só leva em conta características espaciais. e que Park 2019 (RNN) é "apenas o tempo". Provou que foi melhor que os dois unindos essas duas informações. Wang ainda concluí que o ConvLSTM é menos complexo/menos parametros do que o CascadeNet-5 do Wen e, por ter superado Wen, prova que considerar as características espaço-temporais da doença é mais importante do que simplesmente aumentar a complexidade do modelo. Modelo não possuí input flexível (ao contrário de lee/park2024). testaram cenários com [2..6] para prever o próximo. descobriu-se que o melhor foi usando 3 exames de entrada para prever o quarto. (paradóxo, não nescessáriamente quanto maior a série melhor). Esse artigo foi publicado pela Journal of Biomedical Engineering. parece ser uma revista acadêmica legítima e estabelecida na China — não tem sinais óbvios de ser predatória/fake. Ela existe desde 1984, é ligada ao Hospital West China da Universidade de Sichuan e à Sociedade de Engenharia Biomédica de Sichuan.
!! tentar pedir dataset
2024 Lee/Park et al: Bi-GRU com masking layer. dataset privado (Treino: 185.858 VFs de 23.517 olhos de 12.787 pacientes; Teste: 9.459 VFs de 1.053 olhos de 561 pacientes (Permitiu variações de 3 até 80 VFs de entrada)). Fez pointwise forecasting em HVFs 24-2. A principal contribuição foi modelo com flexibilidade no input. um único modelo pode ser usado tanto para um paciente com pouco exame quanto para um paciente com muito exame, sem ter que retreinar. Descobriu que a precisão melhora MUITO até o 10º exame na série (depois melhora pouco) para forecasting curto.
3. Modelos estado da arte
2025 Cost et al: GIN. é cross-sectional (não série temporal) e faz classificação binária (normal ou glaucoma). Pelo menos fala de usar grafo com convolução para ajudar a IA a "enxergar" conexões estruturais/anatômicas melhor que uma rede neural comum. O dataset rotulado permitiu aprendizado supervisionado.
2025 Sriwatana et al: ViT/DINO-ViT. repo
2025 Childress et al: IAR(1) (é modelo estatístico, e não estado da arte de ML/DL). O target não é de HVF (pointwise regression), é o indicador global MD. dataset privado com 1.200 VFs de 42 olhos.
!! tentar pedir dataset
2025 Abbasi et al: Hybrid-VF-Net (Transformes/RNN/CNN). dataset privado (19.437 VFs extraídos de 1.750 sujeitos). Fez pointwise forecasting em HVFs 24-2. O modelo foi testado usando séries de 3, 4 e 5 exames prévios para prever o próximo. Fala das puras CNNs (como a de Wen2019) falharem por serem "estáticos" (não entendem a progressão temporal). Fala das puras RNNs (como Park2019 e Lee2024) tratam os 52 pontos do HVF apenas como uma lista de números, ignorando a anatomia do olho. Ele tambem juntou CNN + RNN e "temperou" com transformers.
2025 Chen et al: VF-Transformer. fala sobre a limitação do UWHVF de "Issue of class imbalance" do e propõe técnica chamada ICDT (tipo de loss func) e Weight Norm para contornar isso. O problema utiliza de séries temporais mas o output do modelo NÃO é um regressao pointwise (um novo exame), mas uma classificação binária: se vai ou não progredir.
2025 Donnipadu et al: FPCA. INÚTIL para o TCC (foi multimodal ao extremo, com até protuários eletrônicosde saúde).
2025 Si et al: ABCI (difusion models). repo